
Scaling a multi-chain wallet infrastructure requires a highly resilient and optimized RPC management system. As the number of supported networks grows, so does the complexity of maintaining low latency and high availability for every request.
What is eRPC and Why Use It in Production?
eRPC is an open-source, fault-tolerant JSON-RPC proxy designed to handle massive multi-chain transaction volumes with high efficiency. It provides specialized features like hedging (sending requests to multiple providers simultaneously to minimize latency), request batching, and intelligent upstream optimization. At Openfort, we transitioned to eRPC to replace a resource-heavy in-house solution, leveraging its ability to scale horizontally and maintain a stable CPU footprint. This ensures that even during high-load periods, our wallet transactions remain fast and reliable across every supported blockchain network without the infrastructure spikes of traditional logging and metrics stacks.
The Problem
When designing our JSON-RPC management system, we had the following requirements:
- Multiple upstreams per chain: It must be possible to configure multiple endpoints for each chain to send requests to, such as Alchemy, drpc, etc., for the main Ethereum chain (with chain ID 1).
- Upstream optimization: The best upstream must be selected for each request based on requirements including latency, cost, load, and rate limits.
- ERC 4337 Support: Openfort supports ERC 4337, for which it relies on ERC 4337-specific JSON-RPC calls. The system must be able to relay the calls and process the responses.
- Error management: Upstreams, networks, and hardware may fail, and errors need to be properly managed (e.g., retry, raise) and communicated.
- Support for local endpoints: Openfort has some in-house JSON-RPC endpoints, and the service must be able to use them.
- Performance: The service will experience high throughput and a high number of simultaneous requests, so great performance and excellent asynchronous I/O handling are a must.
- Caching: The results of some JSON-RPC calls will vary very little in a short time span and can be cached to improve performance and reduce API usage rates. The service must be able to identify and cache such requests.
- Horizontal scalability: The service should have the capacity to scale by adding new instances that are either stateless or can coordinate with other instances.
- Traceability: Logs and traces are vital for quickly identifying and solving service failures.
- Metrics: Metrics must be collected and exposed so that the service's performance and state can be monitored and evaluated.
The Solution
These requirements led us to build a solution written in Go, which gave us very acceptable performance with excellent, built-in concurrency and asynchronous I/O. Go is a language used in more of Openfort's infrastructure, for which Openfort has matured and battle-tested development patterns that keep things maintainable. We used Redis for caching and Elastic for selecting the best upstream for requests. It worked great, scaled horizontally, and served us well, but requirements kept increasing over time, and Elastic was starting to take up too many resources, especially during high-load periods. We faced increasing development and performance requirements, which are bound to increase as Openfort's user base grows.
Before considering looking for alternatives to our in-house solution, we thought of other ways to deal with the biggest issue: Elastic CPU spikes.
- Simplification: The queries evaluated a lot of historic data each time. Reducing the amount of evaluated data or aggregating said data would immediately improve performance at the cost of less accurate results.
- Optimization: We could trace, profile, and improve Elastic deployments and queries. This was a clear must that would periodically take time from the engineering team with (without further study) uncertain results.
- Limit Elastic CPU usage: We could limit the maximum CPU usage of Elastic pods to keep them from starving other pods in the node. Since Elastic's limitation could not be solved with horizontal scaling, the upstream selection would take longer to run and significantly increase the latency of our responses.
Ultimately, we decided to go with a replacement for our in-house tool because it would remove our dependency on Elastic, in addition to the points made in the next section.
In Comes eRPC
At some point, we noticed eRPC, which supported most of the features our in-house product did, as well as the ones we were planning on adding later. We decided to test integrating it into our infrastructure based on the following advantages:
- It met all of the requirements listed above.
- eRPC has a growing community that ensures it will continue to be developed.
- Were development by the original team to stop, its license allows the community and us to take over.
- It is open-source and locally deployable, which was a must.
- It seemed to integrate seamlessly into our GKE environment and our monitoring infrastructure.
- eRPC has extensive documentation and an active community channel.
It also came with features we had not even considered yet:
- Hedging: Preemptively send RPCs to multiple endpoints to pick the response with the lowest latency.
- Request batching: eRPC can smartly batch compatible RPCs into a single request.
- Integrity checks: For requests that benefit from them.
The Migration
The migration started by testing eRPC on a single chain with a few upstreams and checking that it would behave as expected. The next step was to test bundler, or ERC 4337, calls. Once standard and bundler JSON-RPC calls were verified, we gradually added chains and upstreams until we achieved parity with the in-house system, dealing with any issues that arose with specific upstreams.
We submitted a couple of PRs along the way, with fixes for Pimlico providers and JSON-RPC encoding. When every chain and upstream had been verified, we had a trial period where eRPC was deployed alongside our in-house solution in case something went wrong. We took advantage of this period to fine-tune our eRPC configuration by tweaking specific upstreams and providers and properly setting up the caches.
Deployment was straightforward, thanks mainly to eRPC’s documentation and the publicly available Kubernetes configuration examples.
Challenges
eRPC made it easy to identify errors through the metrics dashboard. The team was pretty responsive in the community channels and the GitHub repository, providing complete responses to our inquiries. One of those responses was regarding our biggest issue: failsafe upstreams.
Failsafe upstreams are upstreams configured in eRPC to be used only when the rest of the upstreams have failed. Let's use an example in which chain 1 has three upstreams: A, B, and C, where C is marked as a failsafe upstream. Our expectation was for eRPC to call either A or B when receiving a request, then default to C after trying to forward the request to both A and B. For example, eRPC would send the request to A, which would fail; then to B, which would fail; then to C.
Instead, we found it was giving up after trying A and B without checking C. It turns out, failsafe upstreams will only be called when the non-failsafe upstreams (A, B) are considered unhealthy. Because the unhealthy status is only applied to an upstream after it fails a certain amount of requests, there is a period in which both A and B might be failing but have not been marked as unhealthy.
We were able to get eRPC to behave as we expected with simple changes once we understood the issue. Instead of marking our failsafe upstreams as failsafes, we marked them as normal upstreams and gave them a selection policy that prioritized low request counts. This way, the more the failsafe upstream is used, the lower its priority will be, ensuring it is always tried last as long as the other upstreams are healthy.
Results
Openfort now has a more stable and scalable infrastructure than before, thanks in part to adopting eRPC. It shares the horizontal scalability principles the rest of our components are built with, provides compatible logs and metrics, and maintains stable CPU and memory footprints that make it clear when the service needs upscaling. Combining its efficient code with the right caching and hedging policies has also allowed Openfort to keep latency low. In fact, for the vast majority of requests, most of the latency is caused by JSON-RPC provider response times or the blockchain itself, rather than Openfort’s infrastructure.
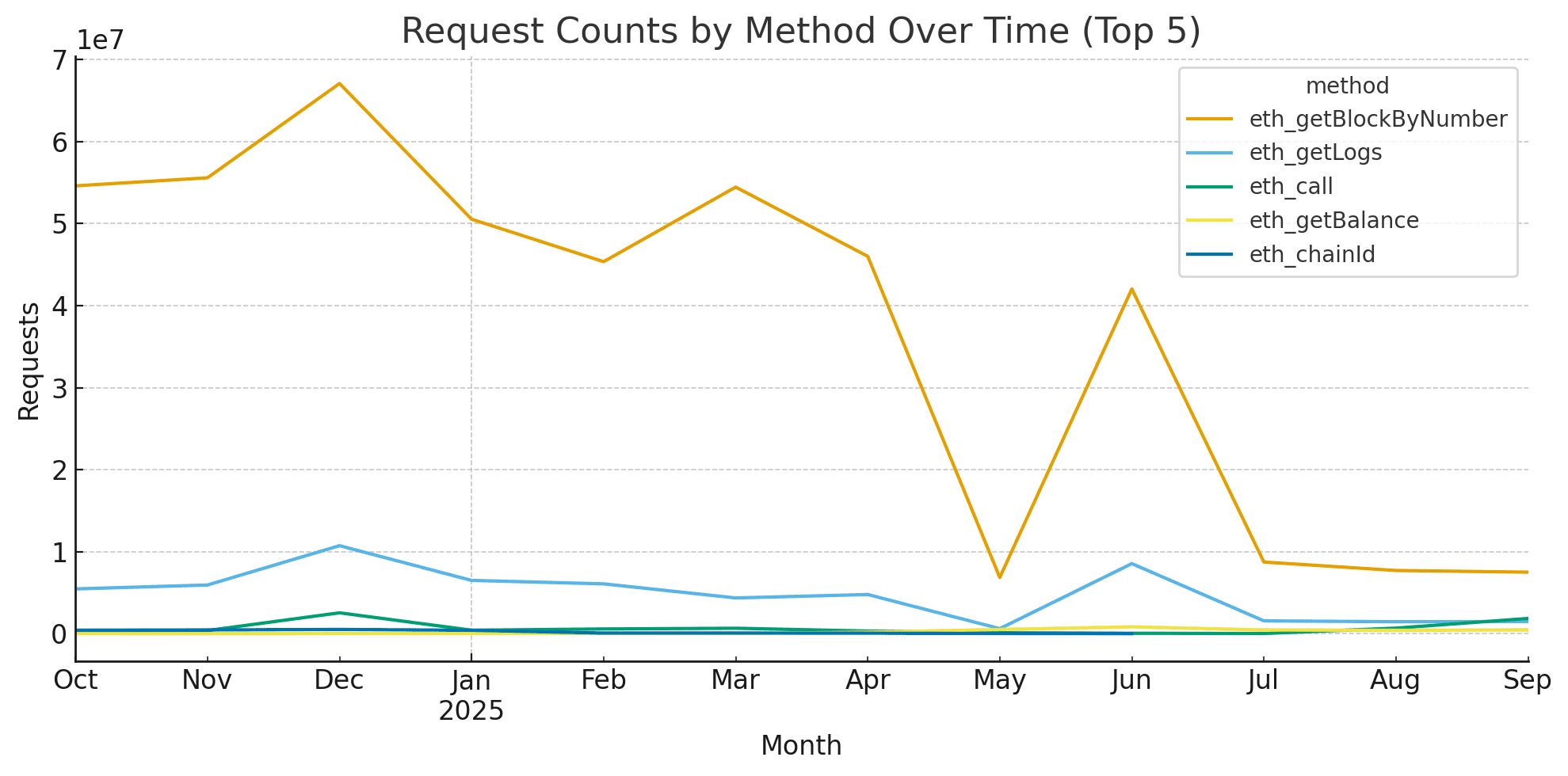
After applying the solution June 2025, the total request volume stabilized:
→ Fewer experimental spikes. → Buffer caching and optimization changes with the RPC aggregation.
Conclusions
eRPC is a great tool that delivers everything it promises, which Openfort has successfully employed to remove a significant performance bottleneck. Properly configuring caching and selection policies, while somewhat tedious, provides vast performance gains and keeps usage rates low. Finally, the open-source nature of the project makes it compatible with Openfort's values, as well as ensuring it will be a long-lived, community-improved project.